2018-03-09
想和你重新认识一次 从你叫什么名字说起。 -----《你的名字》
接着上一篇的~没看的可以去看一下~如果要接着爬图片~登陆是必不可少的~
如果不登录的话~也只能爬到一小部分的~
分析网页图片的加载
先看看最新的图片 https://huaban.com/all
打开开发者工具~刷新~
在XHR里面会找到一个?jejgowlo&max=开头的文件
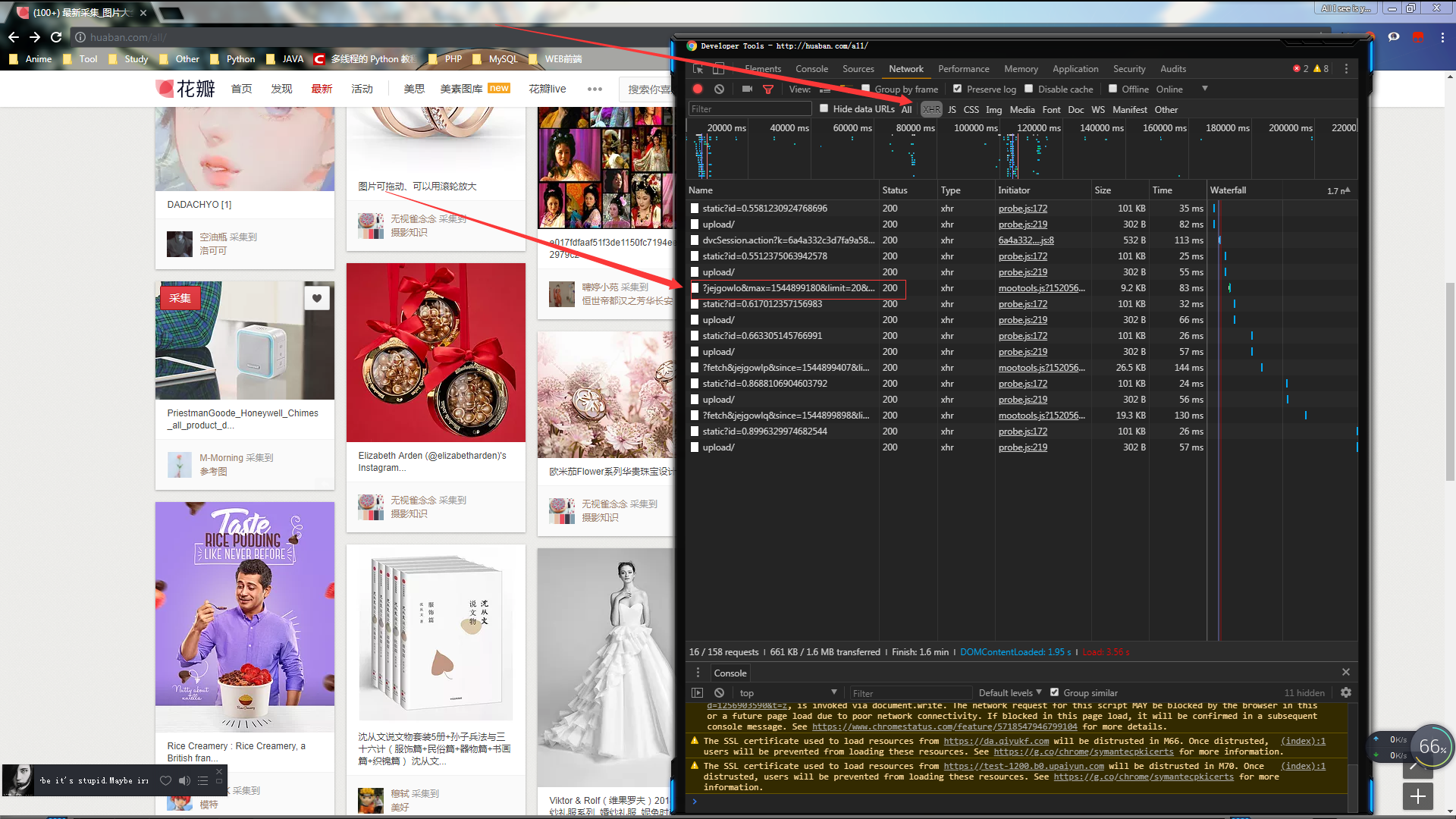
点开它查看一下,这些就是图片信息只有19张~
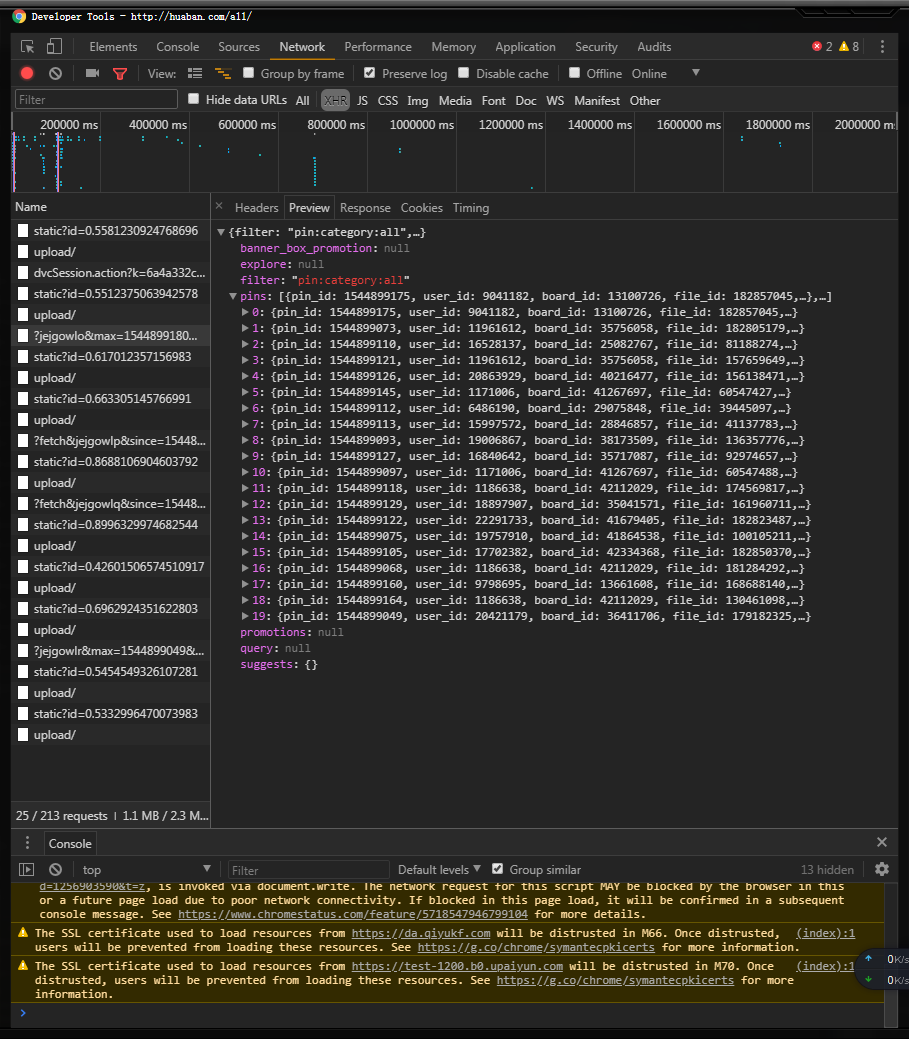
接着打开第一个看看~会发现它是从后19张图片开始的~那前面的19张去哪儿了?~这个问题等会说~
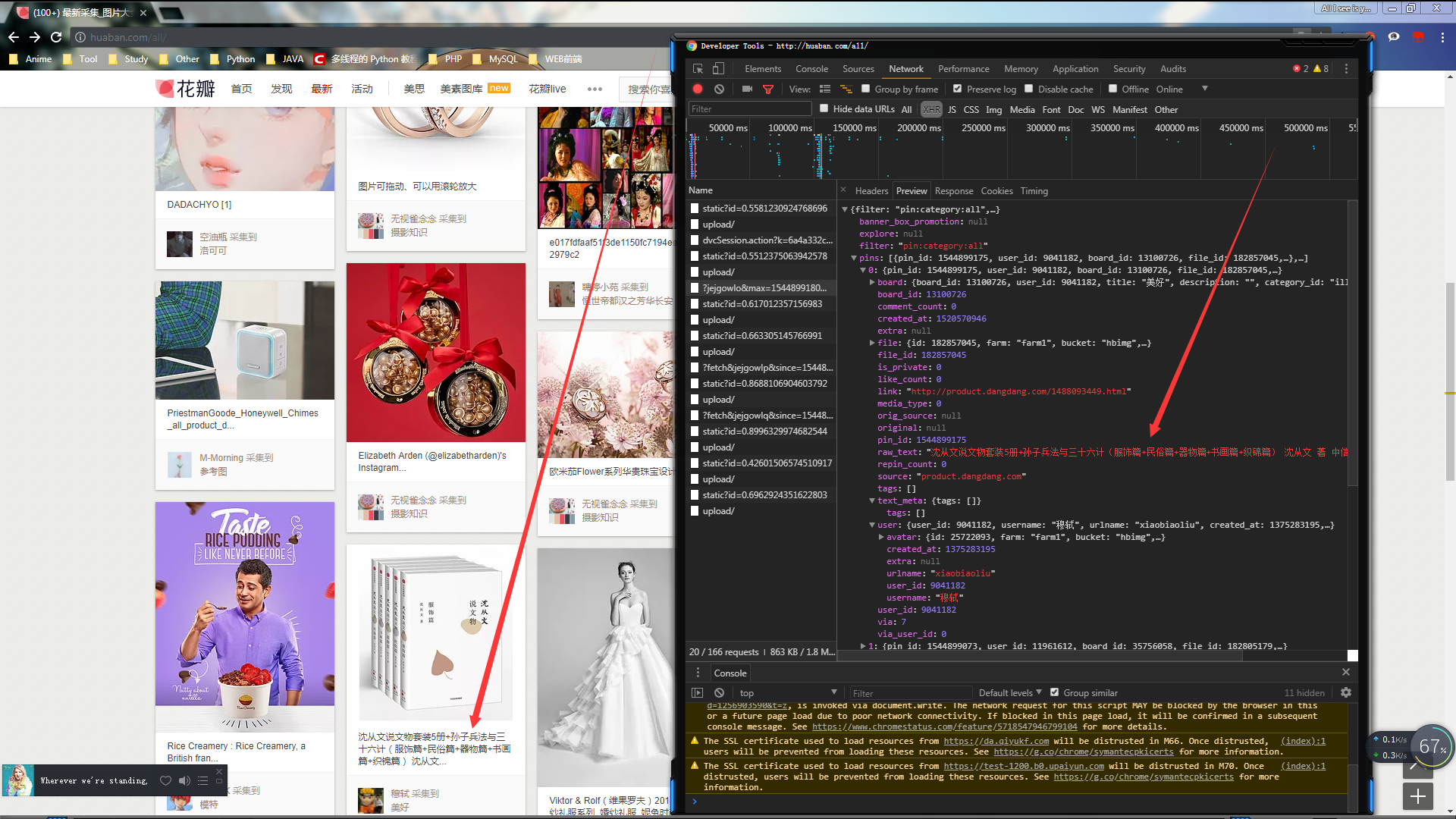
接着往下翻一点~继续抓~又得到一个类似的url
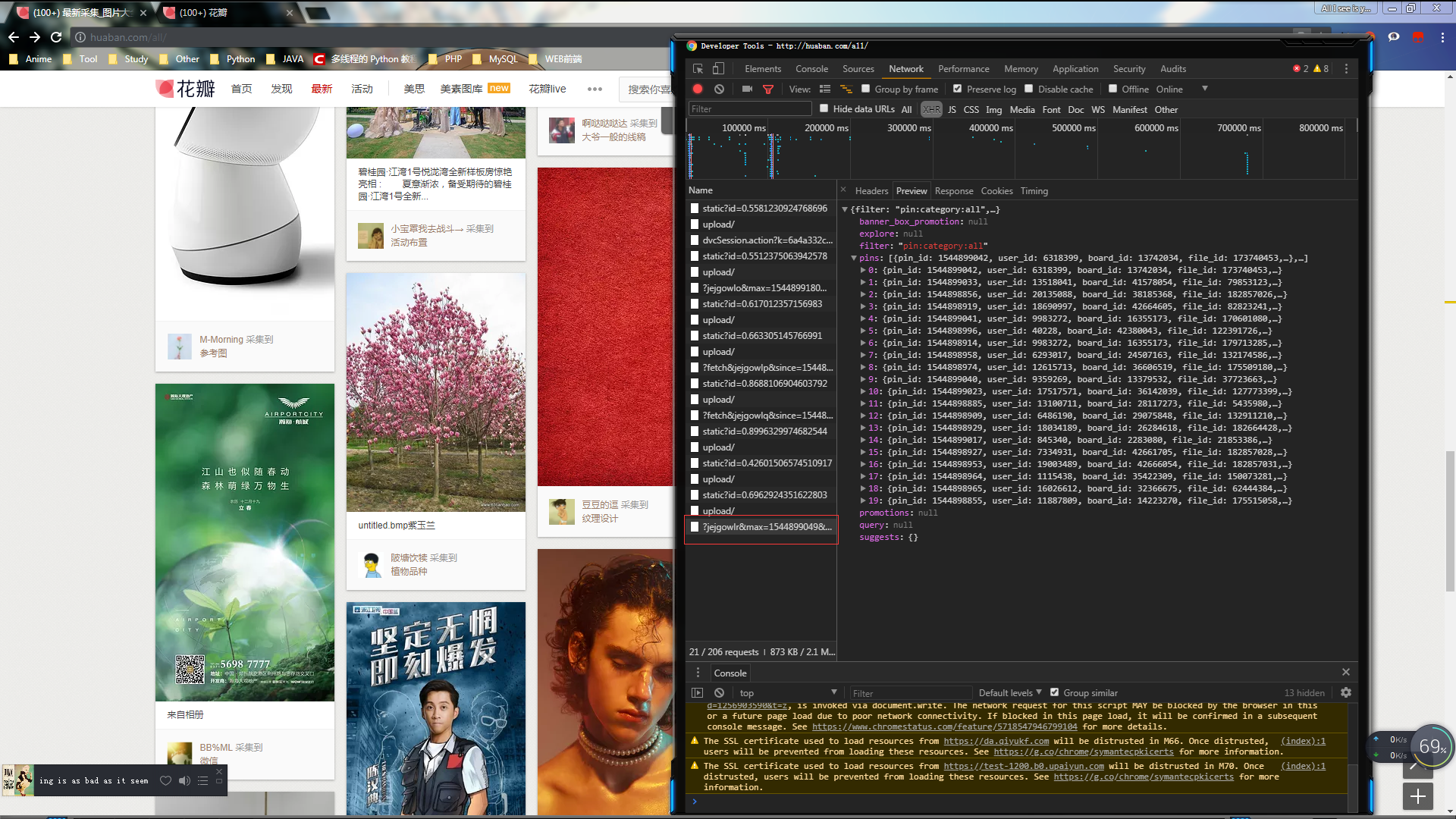
现在可以把第一次抓到的链接和刚才抓到的链接复制出来看一下~
`http://huaban.com/all/?jejgowlo&max=1544899180&limit=20&wfl=1`
`http://huaban.com/all/?jejgowlr&max=1544899049&limit=20&wfl=1`
除了max和?到&的不一样以外~其余是一样的~
?到&中间的我们可以随机生成就ok了~
1 | import random.randint |
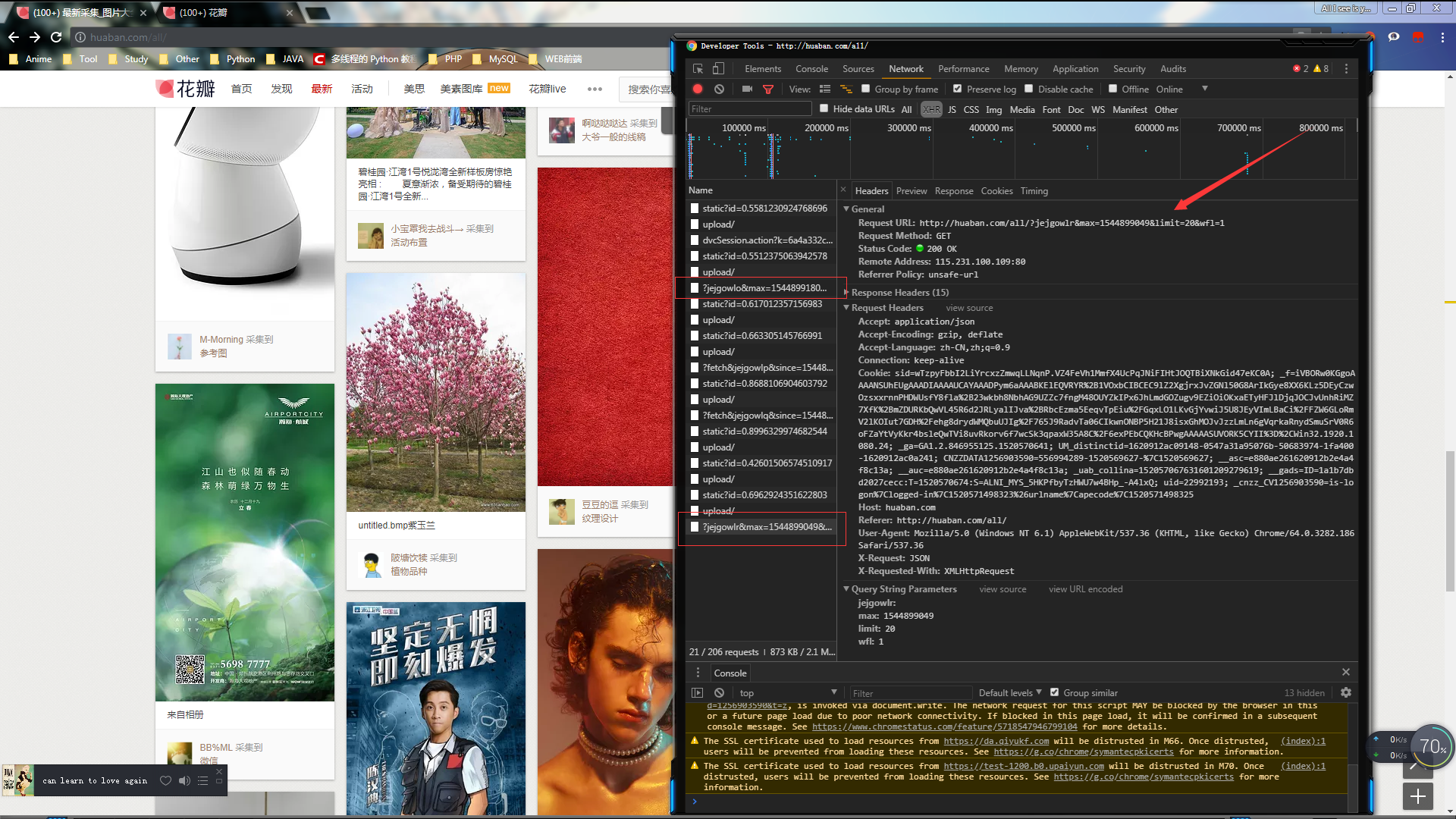
那max是怎么生成的?~其实就是pind_id
回到第一次抓到的url查看最后一个pind_id
会发现第一次抓到的url的最后一个pind_id就是下一次的url的max参数~
由此就可以判断出~它是通过前19张图片的最后一张图片的pind_id来生成后19张图片的~
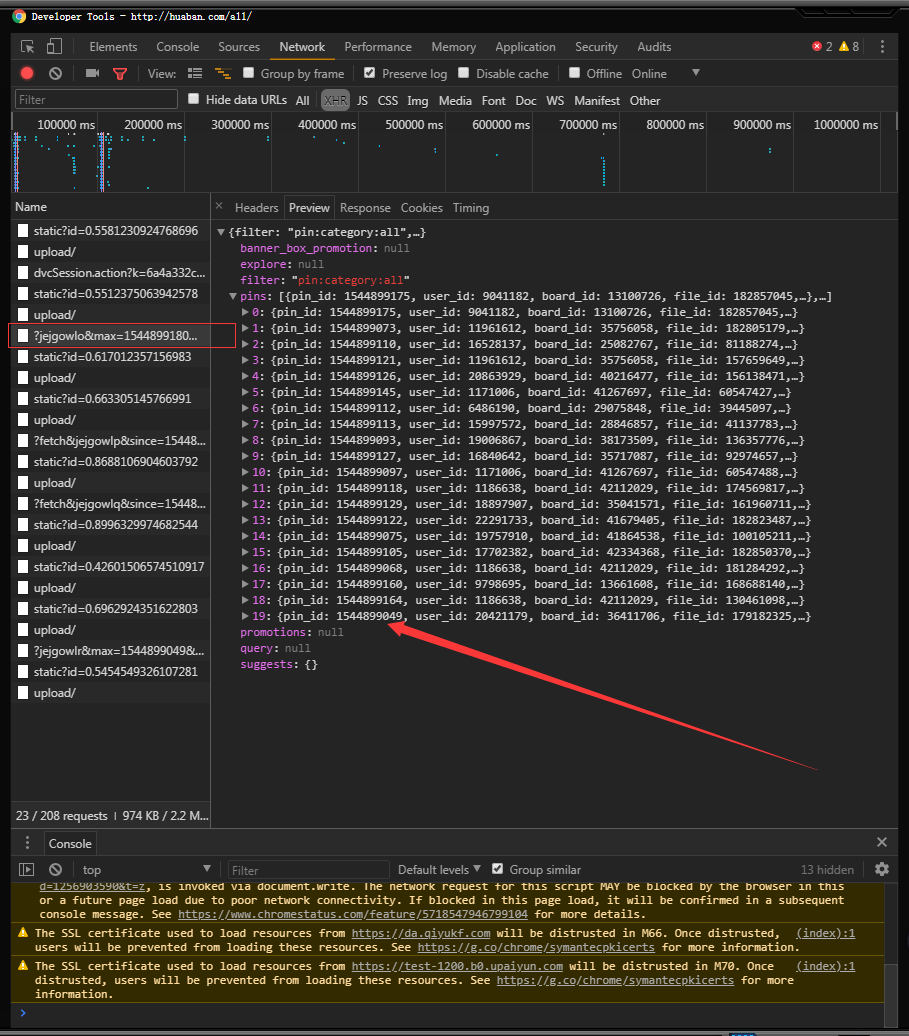
回到刚开始说的为什么是从后19张图片开始的~前面的前19张图片去哪儿了?
其实是在all里面
拼接出来的http://huaban.com/all/?jejgowlr&max=1544899407&limit=20&wfl=1就是前19张的图片
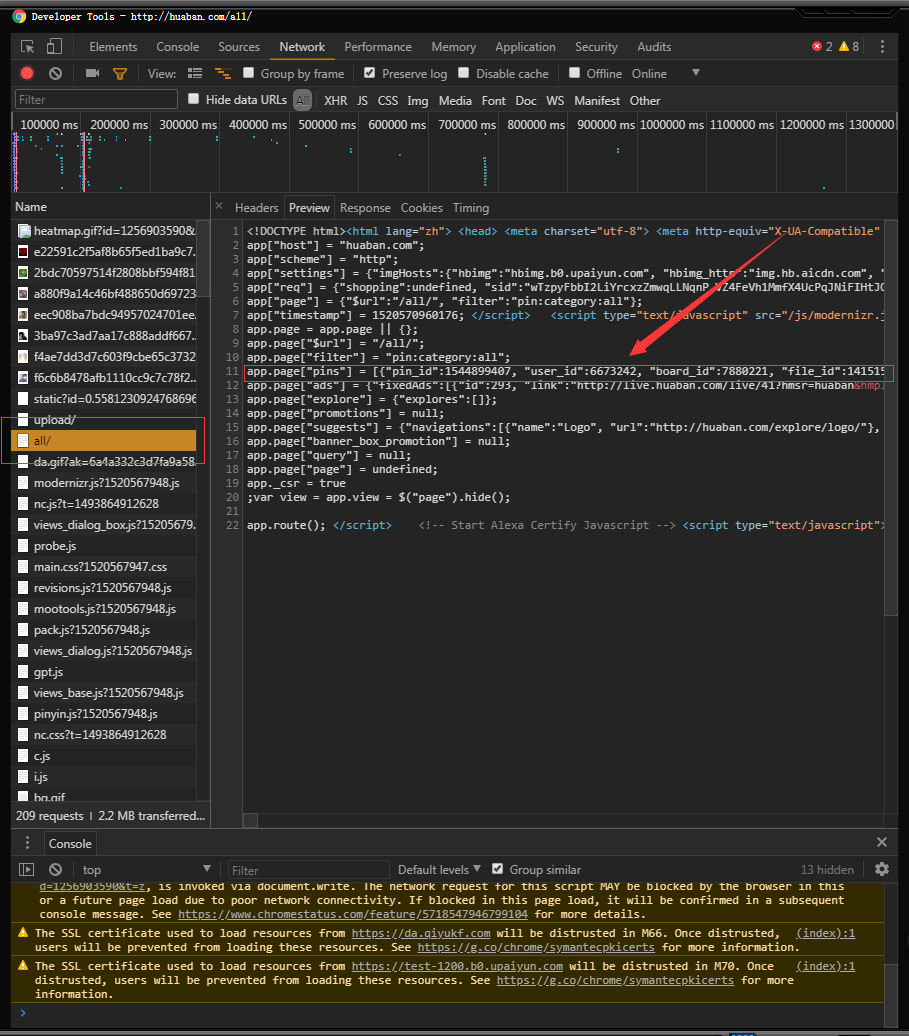
最后在抓取这条连接就可以直接得到最后一个pind_id
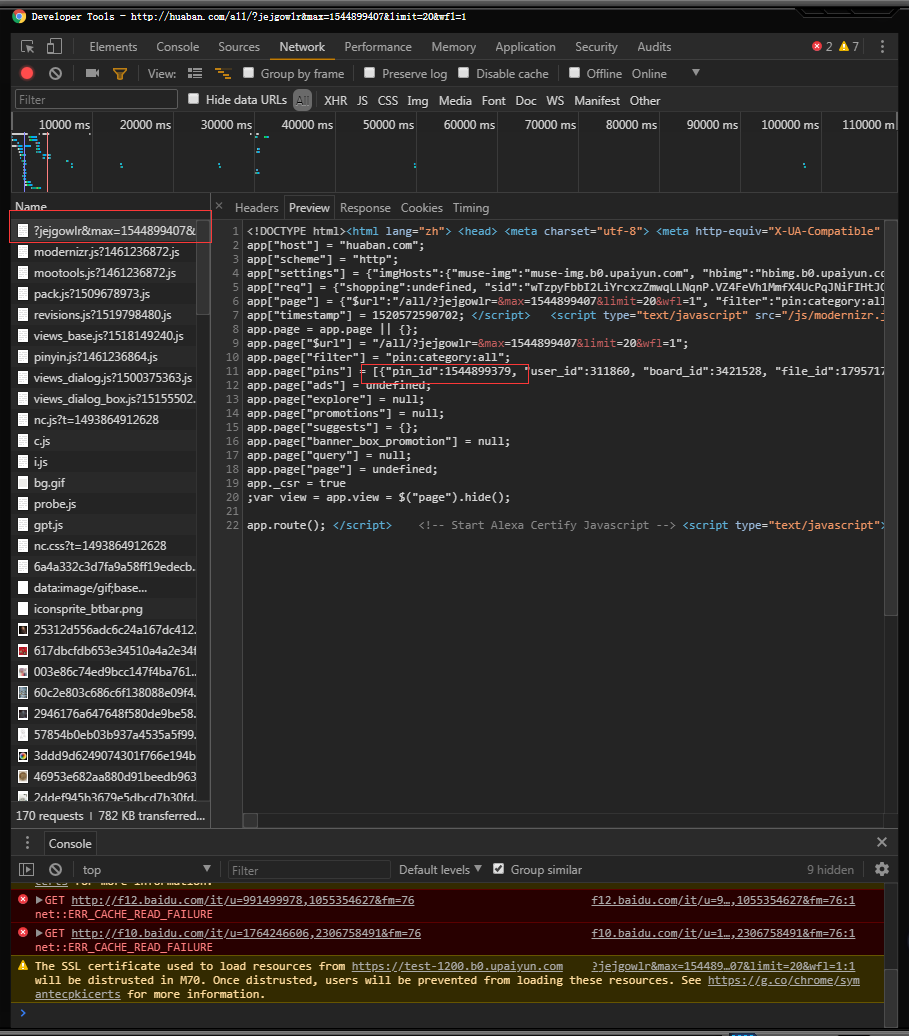
总结出来就是先得到all里面的第一个pind_id拼接之后访问再抓取得到下一轮的图片的pind_id然后再通过上一轮的最后一个pind_id得到下一轮的pind_id
源代码我放到了github里面源代码
爬取关注的和搜索到的类似