语言的含义有内外两层,说出口的并不是全部。 ------薇尔莉特 《紫罗兰永恒花园》
快开学了,趁着还没正式开学,再发一篇爬虫文章,爬取花瓣网的图片
这次分开写,一篇为模拟登陆,一篇为爬取的
需要用到的东西
模块(库)
- requests (需下载)
pip3 install requests
- re (自带)
- json (自带)
- os (自带)
登陆的过程
打开 花瓣网 的首页,按F12或者右键检查打开开发者工具,选择Network,记得要勾选Preserve log
然后输入账号和密码,然后点登陆
接着回到开发者工具中,找到 auth/ 这是一个POST,点击它查看POST的内容
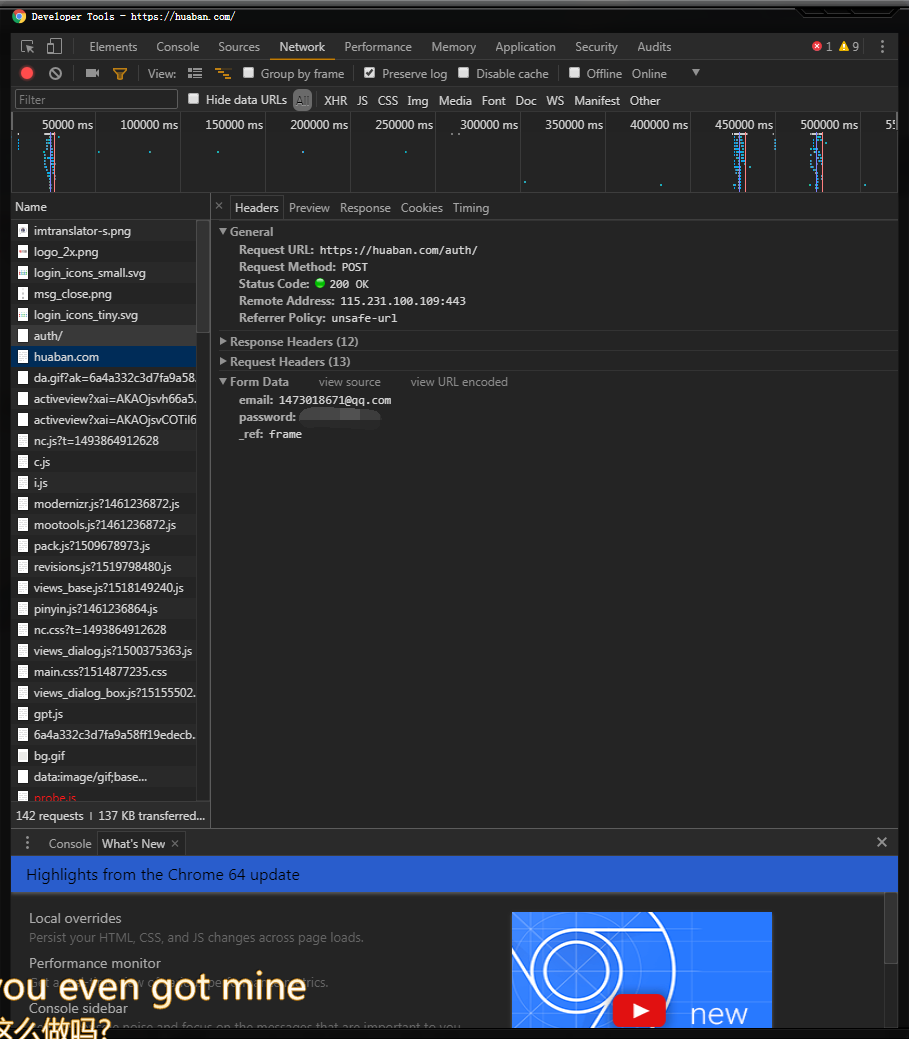
可以看到Form Data的内容就是账号和密码,_ref的参数有两个,一个就是frame另一个是mobile两个都可以登录
知道Form DataPOST的内容就可以构造一个data向https://huaban.com/auth/发送POST了
在POST之前,回到开发者工具,在auth/下面有一个huaban.com/这是登录成功之后重新加载了首页的内容,打开Preview就可以找到用户名这些信息了
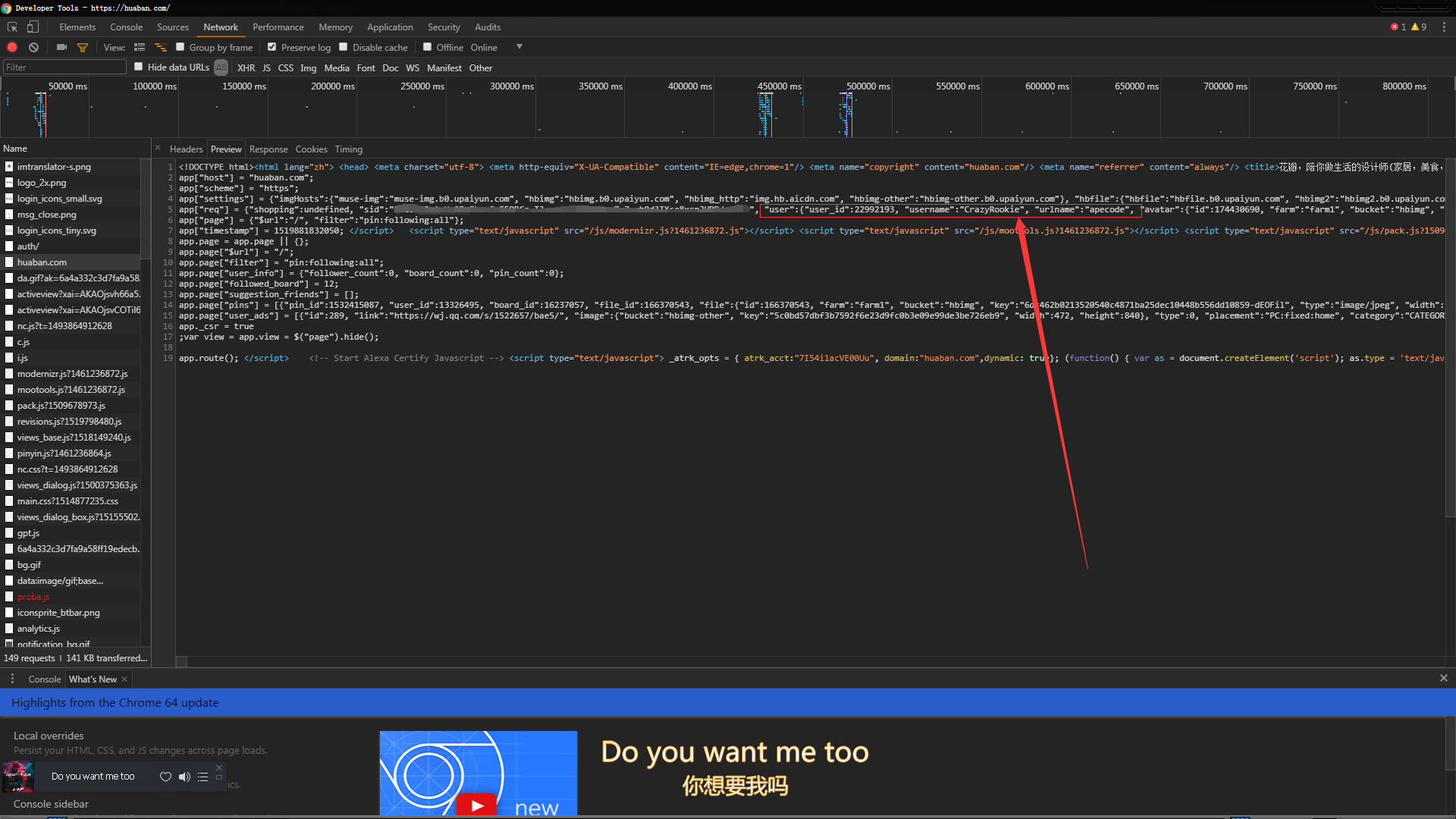
Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
| # -*- coding: utf-8 -*-
import requests
import re
import json
import os
from json.decoder import JSONDecodeError
class LoginHuaBan:
def __init__(self):
if os.path.exists('cookie.json') == False: # 保存cookie到本地
with open("cookie.json", 'w') as c:
c.write('{}')
self.headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Content-Length": "60",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "huaban.com",
"Origin": "http://huaban.com",
"Referer": "http://huaban.com/login/?next=%2F",
"Upgrade-Insecure-Requests": "1",
"User-Agent": """Mozilla/5.0 (iPhone; CPU iPhone OS 10_3 like Mac OS X) AppleWebKit/602.1.50 (KHTML, like Gecko) CriOS/56.0.2924.75 Mobile/14E5239e Safari/602.1"""
}
self.login_url = "https://huaban.com/auth/"
self.session = requests.session()
def islogin(self):
cookie = self.get_cookie()
url = "https://huaban.com/login/?next=%2F"
re_url = re.compile(r'app.page\["\$url"\] = "(.*?)";')
resp = requests.get(url, cookies=cookie).text
get_title = re_url.search(resp)
if get_title.groups()[0] != '/':
return False
else:
return True
def re_get_cookie(self, email, password):
self.data = {
"_ref": "frame",
"email": email, # 输入账号
"password": password # 输入密码
}
self.session.post(self.login_url, self.data, headers=self.headers)
url = "https://huaban.com/"
res = self.session.get(url)
cookie = res.cookies.get_dict()
with open('cookie.json', 'w') as c:
json.dump(cookie, c)
def get_cookie(self):
with open('cookie.json', 'r') as c:
cookie = json.load(c)
return cookie
def get_user_information(self):
cookie = self.get_cookie() # 获取cookie
url = "https://huaban.com/"
html = self.session.get(url, cookies=cookie).content.decode('utf-8')
re_user = re.compile(r'"user":(.*?), "avatar"') # 获取用户的信息(id,用户名,花瓣个人主页)
get_user = re_user.search(html)
try:
json_user = json.loads(get_user.groups()[0] + '}')
return json_user
except JSONDecodeError:
print("账号或密码错误!")
if __name__ == '__main__':
l = LoginHuaBan()
if l.islogin() == True:
print("登录成功!")
print(l.get_user_information())
else:
l.re_get_cookie('', '') # 账号和密码
if l.islogin() == True:
print("登录成功!")
print(l.get_user_information())
else:
print("账号和密码依旧错误!")
|
返回的结果:
登录成功!
{'user_id': 22992193, 'username': 'CrazyRookie', 'urlname': 'apecode'}
花瓣的登陆相对简单~
花瓣网完整的源代码