说残酷的谎言会受到惩罚的。------《Re:从零开始的异世界生活》
那啥~开头本来想说点气势较大的话的~可实在想不出来该说点啥~算了~直接发教程吧~

煎蛋网址: http://jandan.net/
用到模块:
urllib
BeautifulSoup
lxml
安装方式:
因为urllib是自带的,就不用下载了·~
pip install bs4
pip install lxml
ok,安装完成之后~就开始吧~
咱们就搞下面这三个就行了~其他的没啥可看的~

首先来妹子图吧~

看一下图片的地址在哪儿,指着图片右键~点检查,如下图
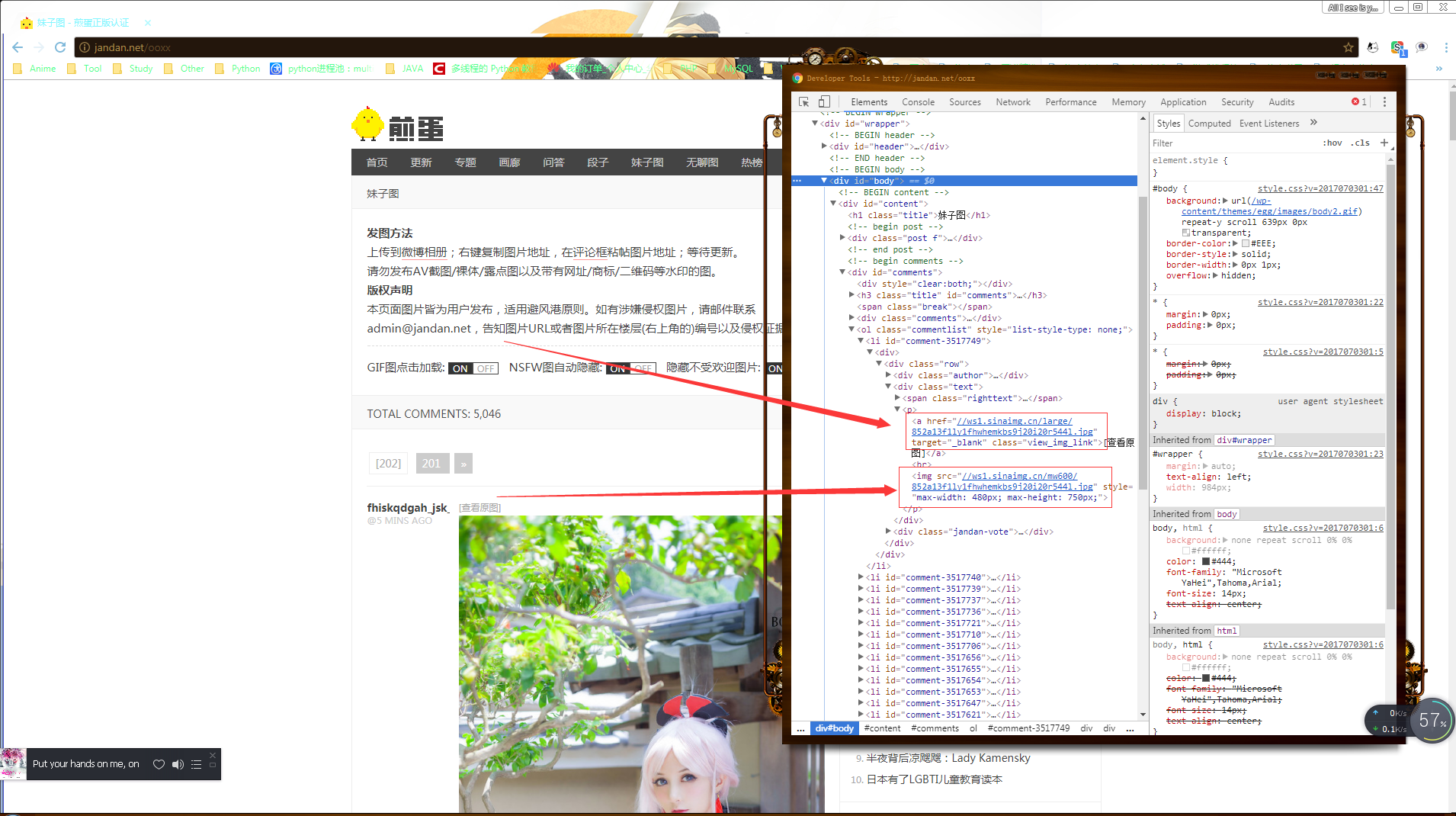
能看见有两个链接~第一个是原图的~第二个是处理过的~咱们肯定要原图的~
接着,找一下这个页面的所有图片
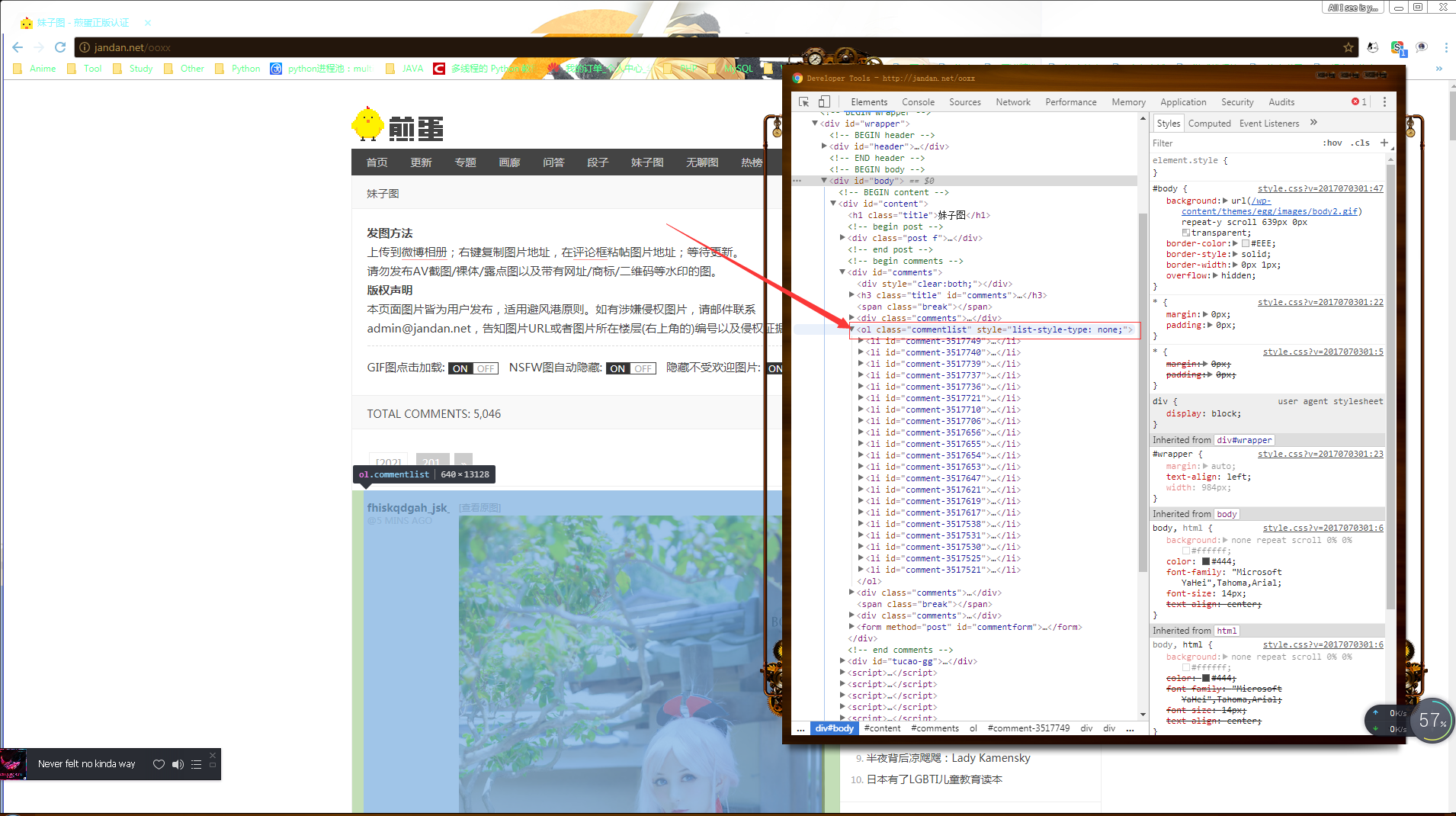
发现他是用无序列表ol~~上代码:
1
2
3
4
5
6
7
8
9
10
11
| import urllib.request
from bs4 import BeautifulSoup
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36"}
ooxx_url = "http://jandan.net/ooxx"
Requesturl = urllib.request.Request(ooxx_url,headers=headers)
openurl = urllib.request.urlopen(Requesturl)
Be = BeautifulSoup(openurl.read().decode('utf-8'),'lxml')
ooxx_image_url = Be.find("ol",class_="commentlist").find_all('a',class_="view_img_link")
for x in ooxx_image_url:
print("http:"+x['href'])
|
上面的代码就可以返回妹子图的地址啦~
![jiandanjiandan_7.png]https://i.loli.net/2018/12/23/5c1f5182936c7.png)
虽然就可以直接这样下载下来的,但是呐~下载下来的图片得有名字呐~接着爬,把发布人的名字和图片的ID也搞下来~继续观察网页源代码~
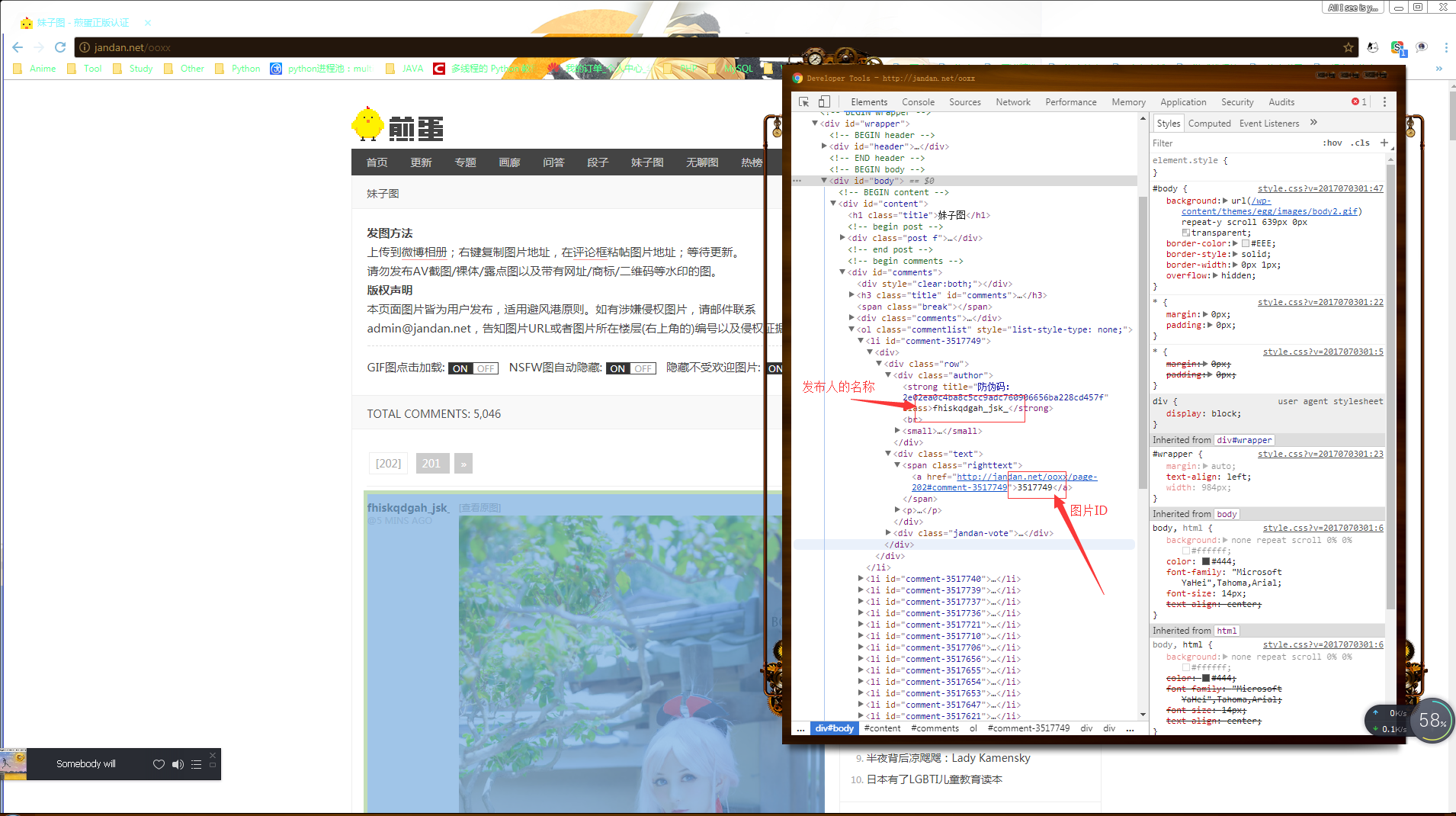
如上图~发布人的名字和图片ID就在这里~也好搞~
1
2
3
4
5
6
7
8
9
10
11
12
| import urllib.request
from bs4 import BeautifulSoup
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36"}
ooxx_url = "http://jandan.net/ooxx"
Requesturl = urllib.request.Request(ooxx_url,headers=headers)
openurl = urllib.request.urlopen(Requesturl)
Be = BeautifulSoup(openurl.read().decode('utf-8'),'lxml')
issue_name = Be.find('ol',class_="commentlist").find_all("strong")
content_id = Be.find('ol',class_="commentlist").find_all("span",class_="righttext")
for x in zip(issue_name,content_id):
print(x[0].get_text(),x[1].get_text())
|
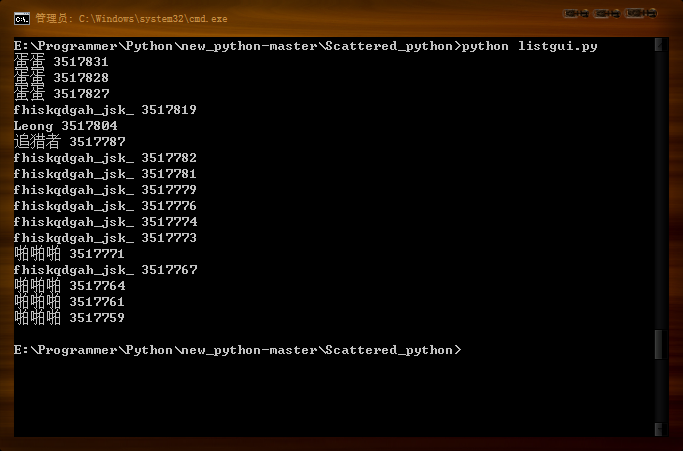
行了~现在可以弄下来了~~
但是呐~还有一个问题~他的页码是从最大的数往下的~继续看网页源代码…

1
2
3
4
5
6
7
8
9
10
11
| import urllib.request
from bs4 import BeautifulSoup
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36"}
url = "http://jandan.net/ooxx"
Requesturl = urllib.request.Request(url,headers=headers)
reopen = urllib.request.urlopen(Requesturl)
Be = BeautifulSoup(reopen.read().decode("utf-8"),'lxml')
BeSoup = Be.find("span",class_="current-comment-page")
for Bs in BeSoup:
print(str(Bs)[1:-1])
|
上面的代码就是可以返回页码~
行啦~可以搞下来了~接下来搞无聊图….
但是~妹子图的源码和无聊图的是一样的~~~只需要改一下url就行了~这里就不重复搞了~直接上段子

发现段子也和妹子图的一样…
1
2
3
4
5
6
7
8
9
10
| import urllib.request
from bs4 import BeautifulSoup
duan_url = "http://jandan.net/duan"
Requesturl = urllib.request.Request(duan_url,headers=headers)
reopen = urllib.request.urlopen(Requesturl)
Be = BeautifulSoup(reopen.read().decode("utf-8"),'lxml')
BeSoup = duan_text = Be.find('ol',class_="commentlist").find_all("p")
for Bs in BeSoup:
print(Bs.get_text())
|
ok了….是不是很简单~这样就出来啦~
整理一下~~
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
| import urllib.request
from bs4 import BeautifulSoup
import shutil
import os
class Ooxx():
def __init__(self,url):
self.headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36"}
self.url = url
def check_folter(self):
if os.path.exists(self.url) == True:
shutil.rmtree(self.url)
os.mkdir(self.url)
else:
os.mkdir(self.url)
def get_page(self):
Requesturl = urllib.request.Request("http://jandan.net/"+self.url,headers=self.headers)
reopen = urllib.request.urlopen(Requesturl)
Be = BeautifulSoup(reopen.read().decode("utf-8"),'lxml')
BeSoup = Be.find("span",class_="current-comment-page")
for Bs in BeSoup:
return str(Bs)[1:-1]
def dowload(self):
self.check_folter()
if select_user == "1" or select_user == "2":
page = int(self.get_page())
while page:
print("````````````````````````````````````````````````````")
print("正在下载第 {} 页".format(page))
url = "http://jandan.net/{}/page-{}#comments".format(self.url,page)
Requesturl = urllib.request.Request(url,headers=self.headers)
reopen = urllib.request.urlopen(Requesturl)
Be = BeautifulSoup(reopen.read().decode("utf-8"),'lxml')
ooxx_image_url = Be.find("ol",class_="commentlist").find_all('a',class_="view_img_link")
issue_name = Be.find('ol',class_="commentlist").find_all("strong")
content_id = Be.find('ol',class_="commentlist").find_all("span",class_="righttext")
for dowload in zip(ooxx_image_url,issue_name,content_id):
print("作者:{} 图片ID:{} 地址:{} OK!".format(dowload[1].get_text(),dowload[2].get_text(),"http:"+dowload[0]['href']))
urllib.request.urlretrieve("http:"+dowload[0]['href'],"{}/{}".format(self.url,dowload[1].get_text()+dowload[2].get_text()+dowload[0]['href'][-4:]))
print("第 {} 页下载完成!".format(page))
page-=1
elif select_user == "3":
page = int(self.get_page())
while page:
print("````````````````````````````````````````````````````")
print("正在下载第 {} 页".format(page))
url = "http://jandan.net/{}/page-{}#comments".format(self.url,page)
Requesturl = urllib.request.Request(url,headers=self.headers)
reopen = urllib.request.urlopen(Requesturl)
Be = BeautifulSoup(reopen.read().decode("utf-8"),'lxml')
duan_text = Be.find('ol',class_="commentlist").find_all("p")
issue_name = Be.find('ol',class_="commentlist").find_all("strong")
content_id = Be.find('ol',class_="commentlist").find_all("span",class_="righttext")
for dowload in zip(duan_text,issue_name,content_id):
print("\n作者:{} ID:{} 内容:{} OK!".format(dowload[1].get_text(),dowload[2].get_text(),dowload[0].get_text()))
try:
with open("{}/{}".format(self.url,dowload[1].get_text()+dowload[2].get_text()+".txt"),'w') as save:
save.write(dowload[0].get_text())
except UnicodeEncodeError:
pass
print("第 {} 页下载完成!".format(page))
page-=1
if __name__ == '__main__':
select_user = input(">>> ")
if select_user == "1":
x = Ooxx("ooxx")
x.dowload()
elif select_user == "2":
x = Ooxx("pic")
x.dowload()
elif select_user == "3":
x = Ooxx("duan")
x.dowload()
else:
print("Srroy,not {}".format(select_user))
|
我在测试的时候,无聊写了一个GUI的爬虫~里面包括了煎蛋~斗图啦~百思不得姐的内容
写完之后自我感觉挺好哒~源代码 看看也行~~

但是在Linux只能打开,没法爬取呐…不知道啥问题~目前只能在Windows下运行~
就这些~有问题请在下面的评论区反馈~~